背景
项目中有一个工作流模型,如下图所示:
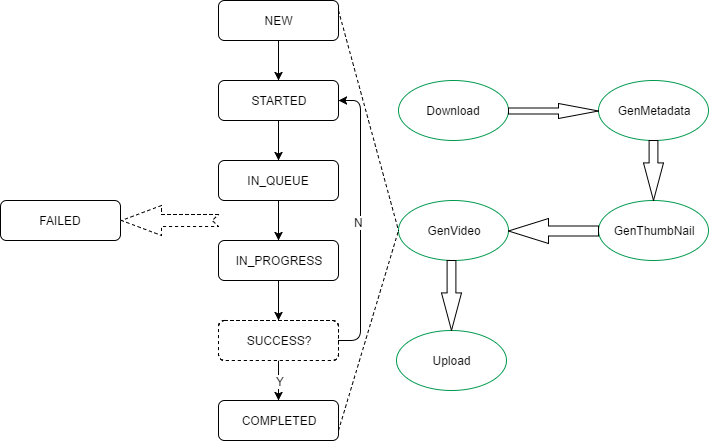
其中:
-
绿色椭圆框体为业务状态;
-
黑色长方框体为业务的作业状态;
-
每个业务状态都会把作业状态从NEW -> STARTED -> IN_QUEUE -> IN_PROGREE -> COMPLETED转一遍.
-
每一个业务状态都会有一个对应的CHECK状态. 在CHECK状态时, 如果SUCCESS检查没过, 则直接退回STARTED状态, 重走一遍CHECK(类似于轮询).
问题描述
当某个业务状态所对应的CHECK状态, 轮询次数过多时, 会发现运行jetty的java进程占用的虚拟内存容量过大, 造成页面加载极其缓慢.
ec2的2GB内存所剩无几:
[ec2-user@ip-172-31-25-152 ~]$ free -m
total used free shared buffers cached
Mem: 2003 1706 296 20 107 405
-/+ buffers/cache: 1193 809
Swap: 0 0 0
top命令发现某java进程的虚拟内存达到了6GB之多, 驻留内存站到了700+MB, 对于2GB的ec2来说比例相当高了.
top - 09:19:19 up 82 days, 15:01, 1 user, load average: 0.58, 0.56, 0.35
Tasks: 89 total, 1 running, 88 sleeping, 0 stopped, 0 zombie
Cpu(s): 15.7%us, 0.7%sy, 0.0%ni, 83.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st
Mem: 2051472k total, 1748936k used, 302536k free, 110560k buffers
Swap: 0k total, 0k used, 0k free, 415216k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8478 ec2-user 20 0 5791m 776m 17m S 12.6 38.7 163:28.09 java
25888 postgres 20 0 329m 16m 13m S 1.3 0.8 0:10.20 postmaster
25911 postgres 20 0 329m 15m 13m S 1.3 0.8 0:08.96 postmaster
25996 postgres 20 0 330m 17m 13m S 1.0 0.9 0:02.05 postmaster
25983 postgres 20 0 330m 17m 13m S 0.7 0.9 0:02.68 postmaster
8537 ec2-user 20 0 2493m 154m 17m S 0.3 7.7 4:14.04 java
1 root 20 0 19636 2408 2084 S 0.0 0.1 0:05.12 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:51.00 ksoftirqd/0
4 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root 20 0 0 0 0 S 0.0 0.0 11:31.83 rcu_sched
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
11 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 netns
12 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 perf
15 root 20 0 0 0 0 S 0.0 0.0 0:00.02 xenwatch
20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 xenbus
21 root 20 0 0 0 0 S 0.0 0.0 2:49.92 kworker/0:1
129 root 20 0 0 0 0 S 0.0 0.0 0:02.30 khungtaskd
130 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 writeback
132 root 25 5 0 0 0 S 0.0 0.0 0:00.00 ksmd
133 root 39 19 0 0 0 S 0.0 0.0 0:00.00 khugepaged
134 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 crypto
135 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kintegrityd
136 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
138 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kblockd
488 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 md
查看对应进程, 发现正是运行jetty容器提供HTTP服务的进程:
[ec2-user@ip-172-31-25-152 ~]$ ps -ef| grep 8478
ec2-user 8478 1 11 May10 ? 02:43:37 java -jar /home/ec2-user/jetty-latest/start.jar
ec2-user 26202 26167 0 09:19 pts/0 00:00:00 grep --color=auto 8478
跟踪和分析过程
-
用jmap把问题进程的heap抓下来:
jmap -heap:format=b 8478jmap是JDK附带的工具, 可以通过指定PID把对应java进程的heap和memory dump出来.
上面的jmap命令运行结束后, 会在当前目录生成heap.bin文件.
-
将heap.bin下载到安装有Eclipse Memory Analysis Tool的机器上, 直接打开heap.bin
-
Eclipse Memory Analysis Tool提供了强大的图形化分析功能.
-
分析后发现大量的ChannelSftp对象存放在一个vector里, 被强引用, 占据了堆空间, 没有及时释放, 也无法被GC回收.
跟踪代码, 发现在业务状态所对应的CHECK状态时的动作是创建一个ssh Session连到ec2上, 检查对应业务状态的log文件是否包含有”SUCCESS”字串.
创建ssh Session的动作, 是通过com.jcraft.jsch包来做的, 流程如下:
-
创建com.jscraft.jsch.Session实例;
-
通过Session创建com.jscraft.jsch.ChannelSftp实例;
-
通过ChannelSftp获取远端ec2上文件的内容;
代码逻辑如下:
public String readTextFile(SshInfo sshInfo, String path){
...
try{
Session session = getSessionConnected(sshInfo);
ChannelSftp sftpChannel = (ChannelSftp)session.openChannel("sftp");
sftpChannel.connect();
OutputStream outputStream = new OutputStream();
sftpChannel.get(path, outputStream);
...
}catch(Exception e){
throw new AppException(...);
}
}
com.jscraft.jsch是开源的第三方包, 下载了一份源码.
跟踪到ChannelSftp类, 发现:
-
在ChannelSftp的Channel基类的构造函数中, 将Channel对象自身加到一个static Vector pool中去;
-
在Channel基类的del方法中, 才将该Channel对象从pool中移除; ( 移除后强引用关系丢失, GC才会自动回收Channel对象 )
继续跟踪在何处调到del, 发现在Channel的disconnect方法会调到del方法.
逻辑和rootcause很清晰了, ChannelSftp用完后要显式的调用disconnect, ChannelSftp对象才能被GC回收.
真是一个低级错误.