Welcome to JH's Blog!
-
Https的SSL/TLS协议分析
背景
本文基于访问 https://mail.google.com 的WireShark抓包结果分析Https和SSL/TLS协议握手过程, 操作过程为:
-
打开chrome浏览器并访问 https://mail.google.com 首页
-
关闭chrome
这个过程客户端chrome和mail.google.com之间新建了3个TCP连接.
为便于描述, 通过Wireshark筛选了其中一个连接的数据做分析.
总体上讲,经历了一下几个大的阶段:
-
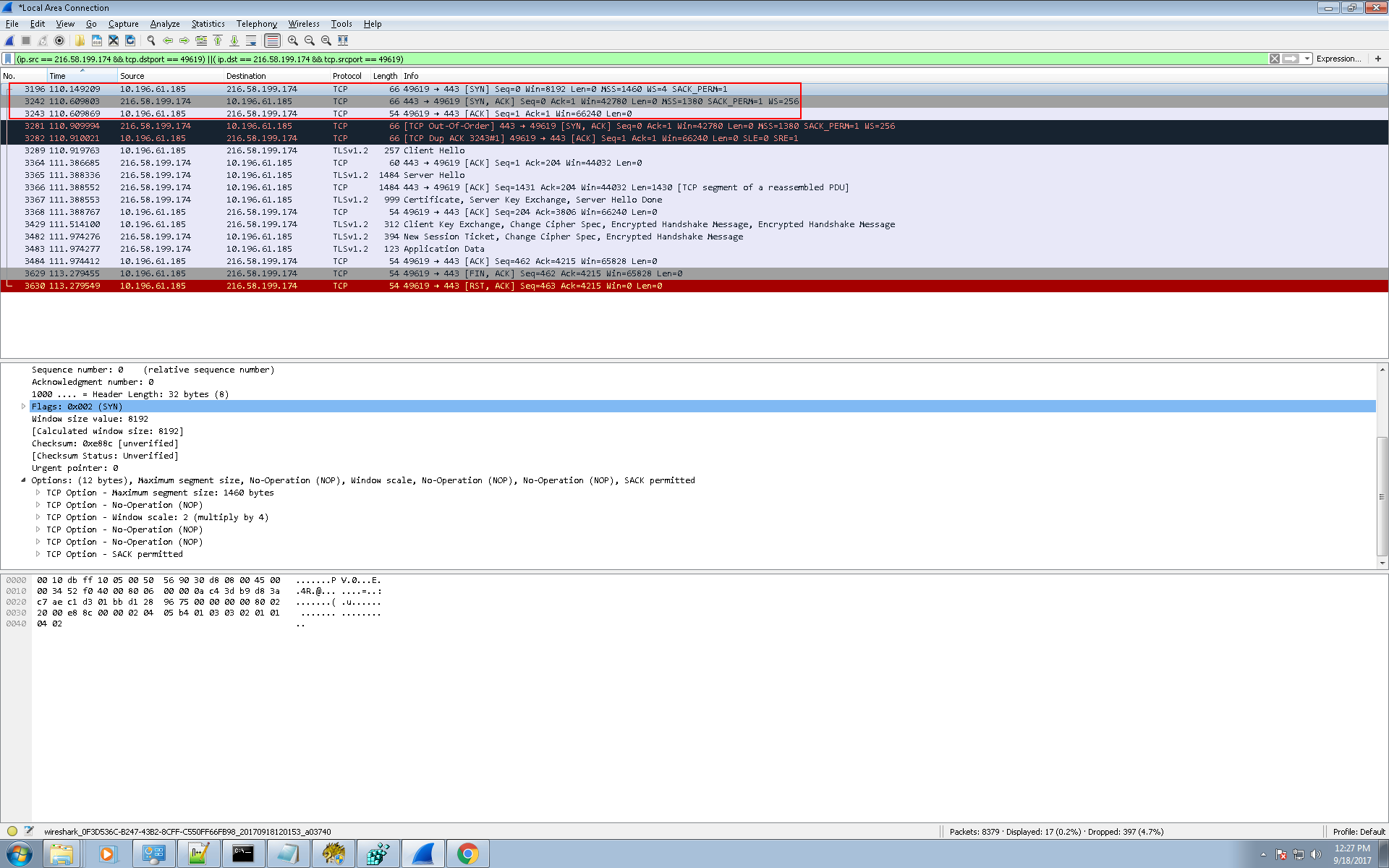
TCP的三路握手
-
TLSv1.2协议握手
-
应用数据传输
-
断连
第一阶段 TCP的三路握手
没什么好说的,见图:
第二阶段 TLSv1.2协议握手
-
第一步 客户端往服务端443端口发一个Client Hello报文
应用层协议为Secure Socket Layer, 如下图所示:
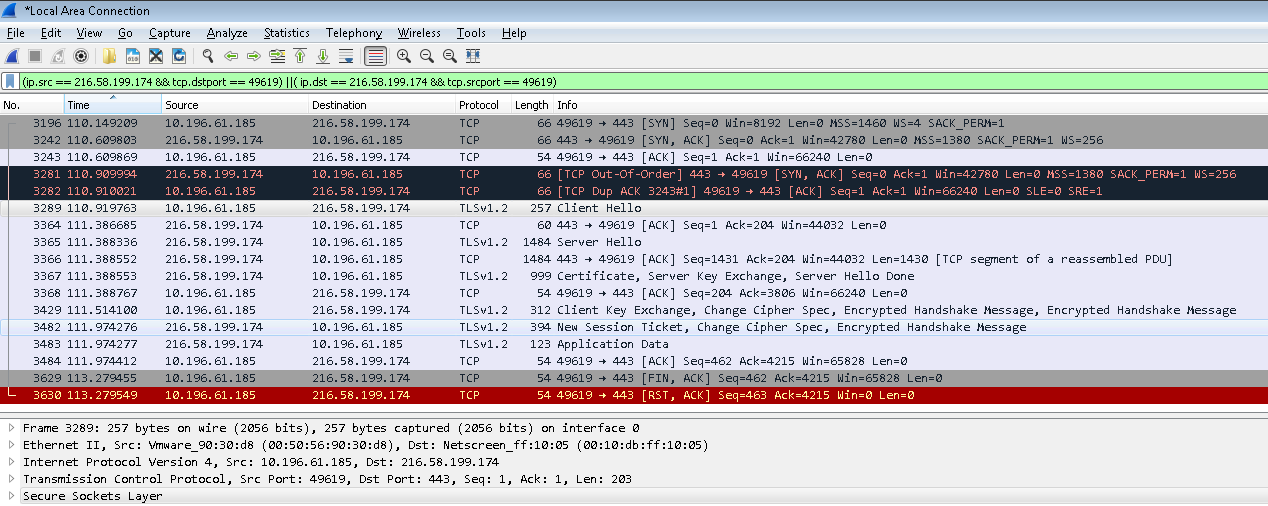
Secure Socket Layer的具体内容如下图所示, 包括:
-
Content Type为Handshake
-
Version为TLS v1.0
-
Length表示Secure Socket Layer的数据长度
-
Handshake Protocol的详细内容:
-
Handshake Type为Client Hello, 值为1
-
Length表示Handshare Protocol的数据长度
-
Version为TLS 1.2
-
随机数: 这是客户端生成的随机数, 稍后用于生成”对话密钥”
-
Session ID Length为0(还没有Session ID生成, 故Length为0)
-
Cipher Suites: 客户端支持的加密方法
-
Compression Methods: 客户端支持的压缩方法
-
Extension部分(略)
-
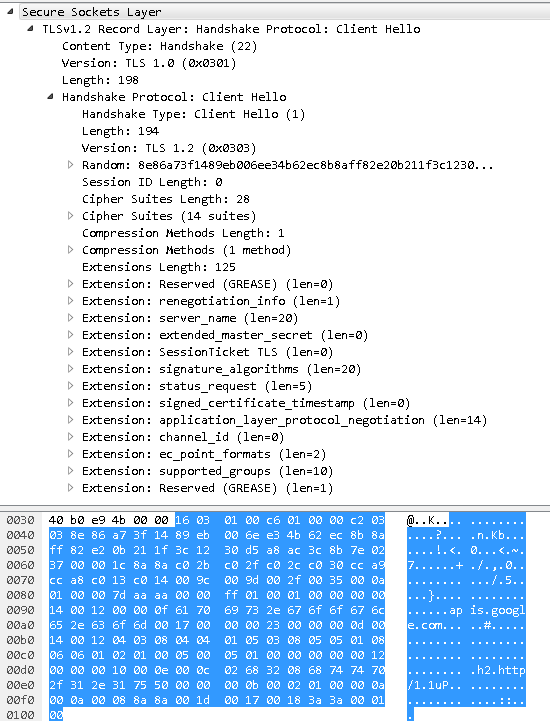
-
-
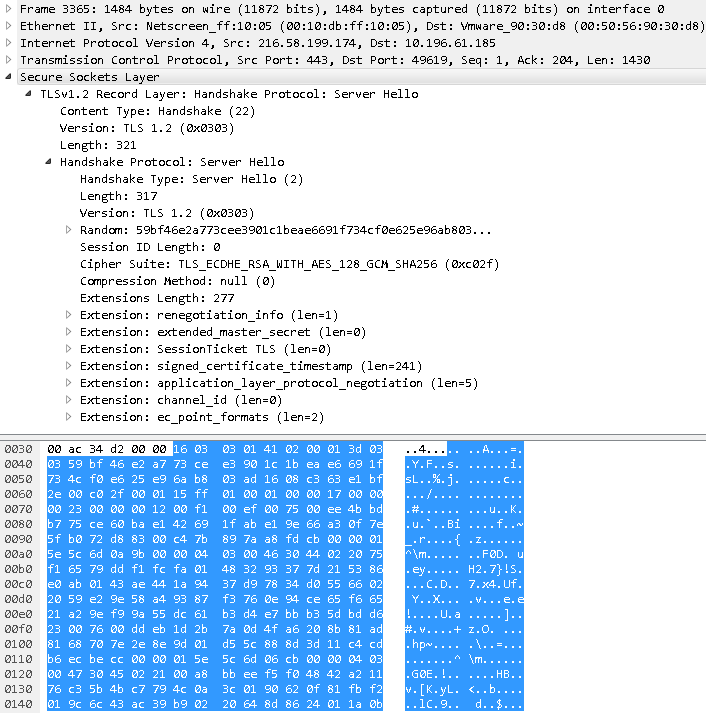
第二步 服务端首次回应Server Hello报文
应用层协议同样为Secure Sockets Layer, 具体内容如下图所示:
-
Content Type为Handshake
-
Version为TLS v1.2
-
Length表示Secure Socket Layer的数据长度
-
Handshake Protocol的详细内容:
-
Handshake Type为Server Hello, 值为2
-
Length表示Handshare Protocol的数据长度
-
Version为TLS 1.2
-
随机数: 这是服务端生成的随机数 ( 这是Https协议握手过程的第二个随机数 )
-
Session ID Length为0(还没有Session ID生成, 故Length为0)
-
Cipher Suite: 服务端决定的加密算法
-
Compression Methods: 服务端决定的压缩方法, 此处为null
-
Extension部分
-
需要注意的是, 在协议的Extension部分, 服务端将后面步骤用到的证书的时间戳放在signed_certificate_timestamp字段发给了客户端.
-
-
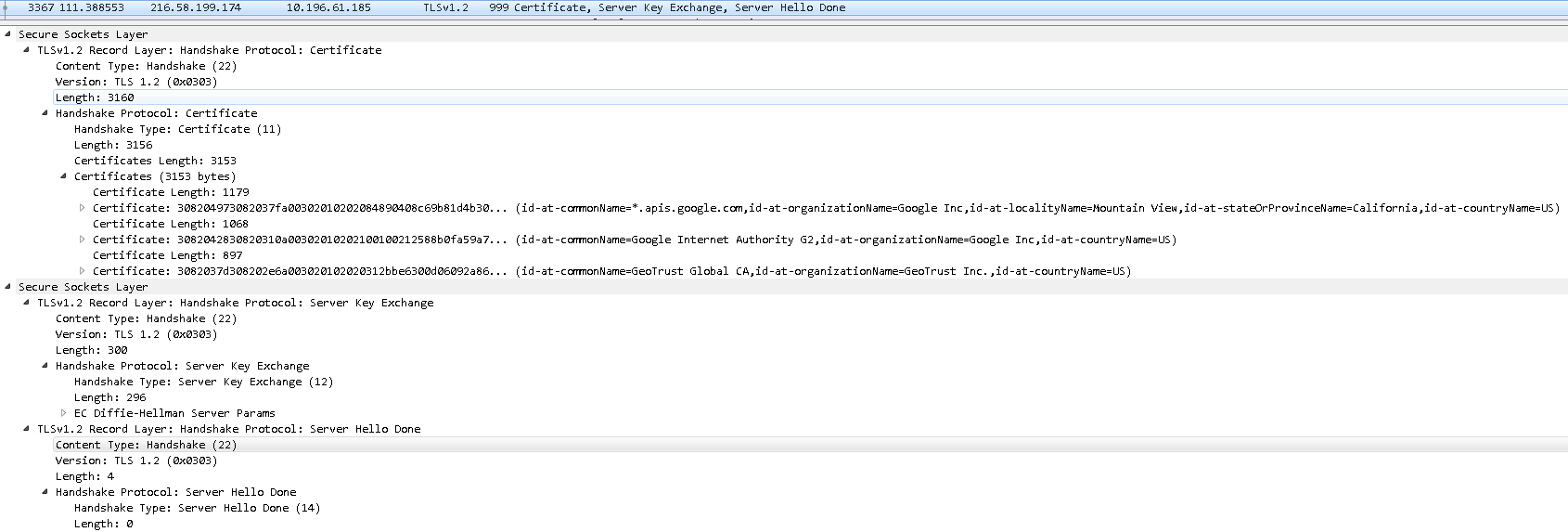
第三步 服务端将证书发给客户端
这个报文比较长, 是3个TCP分节的combine.
逻辑上包含三个TLSv1.2 Record Layer的报文:
-
Handshake Protocol为”Certificate(11)”: 包含证书
-
Handshake Protocol为”Server Key Exchange(12)”: 包含Diffie-Hellman算法的服务端证书公钥, 证书本身的数字签名
-
Handshake Protocol位”Server Hello Done(14)”: 表示服务端的Server Hello完成
-
-
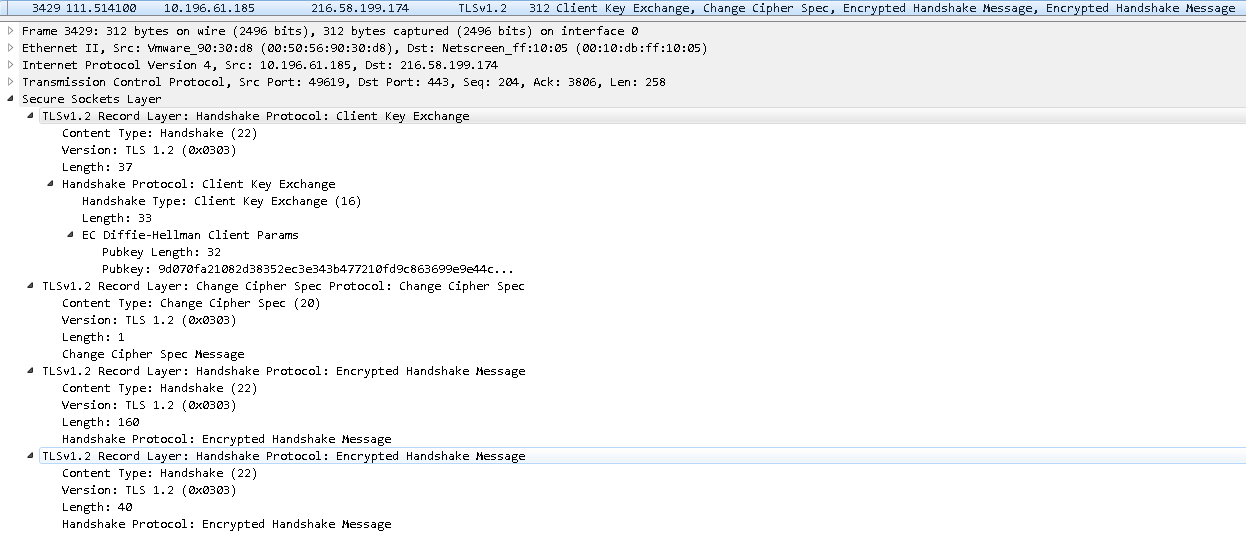
第四步 客户端回应服务端
逻辑上包含如下几个TLSv1.2 Record Layer的报文:
-
Handshake Protocol为”Client Key Exchange(16)”: 包括Diffie-Hellman算法的客户端公钥
-
Change Cipher Spec报文: 告知服务端, 客户端已经切换到之前的Cipher Suite来加密数据并传输
-
第三个随机数的加密数据
此外, 客户端使用前面的两个随机数, 已经刚刚生成的第三个随机数, 使用之前与服务器确定的加密算法, 在客户端生成一个Session Secret.
-
-
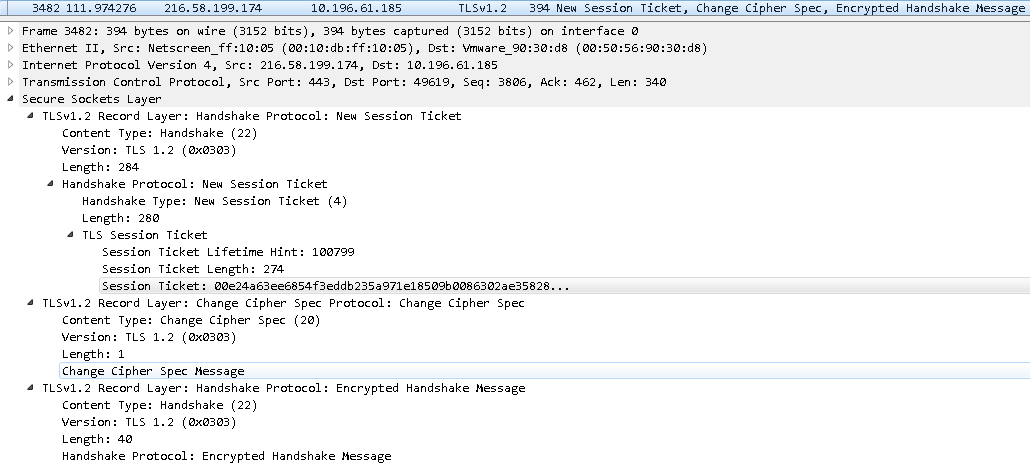
第五步 服务端再次响应客户端
逻辑上包含如下几个TLSv1.2 Record Layer报文:
-
Handshake Protocol为”New Session Ticket(4)”的报文: 包含Session Ticket
-
Change Cipher Spec报文: 告知客户端, 服务端已经切换到之前的Cipher Suite来加密数据并传输
-
加密的Finish消息 ( 用于验证之前通过握手建立起来的加解密通道是否成功 )
-
至此, TLSv1.2的握手过程完成。
往后, 服务端和客户端就可以通过TLSv1.2传输加密数据了, 加密数据的TLSv1.2 Record Layer的Content Type为Application Data(23).
总结
SSL/TLS在握手阶段使用的是非对称加密, 在传输阶段使用的是对称加密.
传输阶段的对称加密的密钥是基于非对称算法在不安全的网络上让会话双方在握手阶段生成的。
兼顾了安全和性能。
-
-
记录一个的Spring Boot Maven Plugin的issue
背景
最近几天在把一个Restful后台项目从Spring MVC移植到Spring Boot.
移植的目的有两个:
一是趁机会学习一下Spring Boot;
二是Spring Boot Secutity提供了很好的Restful API的鉴权接口.
移植的过程遇到不少问题, 尤以本文打算记叙的这个问题最为奇葩.
问题介绍
这个Restful后台项目所用的数据库是MS SQL Server, SQL Server的JDBC Driver, 是在微软官网上提供的jar包下载, 似乎并没有任何Maven Repository对此jar包做官方提供.
在这样的背景下, 我能想到的最佳引用方式就是在pom.xml引用本地lib目录的jar包, 如下代码:
<dependency> <groupId>com.microsoft.sqlserver</groupId> <artifactId>sqljdbc42</artifactId> <version>4.2</version> <scrope>system</scrope> <systemPath>${project.basedir}/lib/sqljdbc42-4.2jar</systemPath> </dependency>然后再在spring-boot-maven-plugin的配置中将includeSystemScope设置为true:
<plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> ... <includeSystemScope>true</includeSystemScope> ... </configuration> </plugin>这样在编译jar包的时候, sqljdbc42-4.2.jar被打在了BOOT-INF\lib里面.
用mvn spring-boot:run可以正确加载并且运行.
但是该项目是一个Web应用, 最终是要发布在tomcat里面的, 所以在发布之前是要被打成war包的.
问题来了, 当在pom.xml里加上如下选项, 将其打为war包时, sqljdbc42-4.2.jar被打进了WEB-INF\lib-provided里面, 而不是期望的WEB-INF\lib.
<packaging>war</packaging>maven的scope分为如下几种:
-
compile
默认Scope. 设置为compile scope的依赖, 在编译, 测试, 运行阶段, 这个artifact对应的包都会在classpath中, 意味着, 设置为compile scope的依赖, 会被打入发布的jar, war包之中.
-
provided
provided指的是目标容器已经provide了这个依赖包/artifact. 所以设置为provided scope的依赖, 只在编译, 测试阶段会出现在classpath中.
而在运行阶段, 由于我们假定目标容器会provide这个依赖包/artifact, 所以这个依赖包不会被打包进入发布的jar, war之中.
-
runtime
运行时scope. 只是在测试, 运行阶段会出现在classpath中.
-
test
测试scope, 只有在测试编译和测试运行阶段可用.
-
system
system与provided类似, 但是必须显式的提供一个本地文件系统中jar文件的路径. 将一个依赖设置为system的同时, 必须提供一个systemPath, 指明本地文件系统中jar文件的路径.
问题的分析和解决
从maven的scope的说明文档上, system这个scope是不被推荐使用的.
而且”system和provided类似”, 似乎本问题(sqljdbc42-4.2.jar被打进war包的WEB-INF\lib-provided而不是WEB-INF\lib)的存在也是合理的.
所以解决这个问题无外乎几个办法:
-
引用公共或自己定制的Maven Repository中的sqljdbc42-4.2.jar
-
看spring-boot-maven-plugin是否有提供选项将system scope的jar打包路径从WEB-INF\lib-provided变为WEB-INF\lib
自己定制Maven Repository这个办法太麻烦了.
考虑到发布的便利, 我决定优先采用第二种办法.
下了一份spring-boot的源码(包含spring-boot-maven-plugin的源码), 读了war包打包部分的逻辑, 发现并没有办法动态配置指定scope或特定jar包的打包路径.
maven本身有提供
这样的标签, 但是这个是用于定制target/目标目录结构的. 本文问题是出在war包的打包结构上, 为打war包负责的模块应该是spring-boot-maven-plugin.
居然没有提供这样的动态配置接口…
-
-
apache tomcat 8源码学习(1) - start流程
背景
在改进一个基于一个Servlet Web框架(Draco)的时候, 对Servlet标准产生了些许兴趣(现在已经出到Servlet 4, 支持HTTP/2.0), 接下来便想看一下Servlet的实现。
便翻出了apache tomcat 8的源码, 这一看, 就有点停不下来, 于是从tomcat instance的start流程入手, 对tomcat从上层到底层的源码和机制都梳理一下.
tomcat的start
tomcat下载后, 我们启动都是通过bin\startup.sh来启动.
startup.sh是一个shell脚本, 调用到的是bin\catalina.sh start, 后跟其他参数.
catalina.sh也是一个shell脚本, 这个脚本稍微复杂了一些, 不过主要都是在处理start, stop, run, debug以及其他参数, 对于start流程, 其核心是调用到下面的Java命令:
$JRE_HOME/bin/java ... org.apache.catalina.startup.Bootstrap ... start可见, 对于start的过程, 其入口类是org.apache.catalina.startup.Bootstrap类
org.apache.catalina.startup.Bootstrap
静态区域
主要做了以下几件事情:
-
获取catalinaHomeFile ( 可通过Globals.CATALINA_HOME_PROP获取,默认为bootstrap.jar )
-
获取catalinaBaseFile ( 可通过Globals.CATALINA_BASE_PROP获取 )
start方法
init()获取catalinaDaemon
-
initClassLoaders()
-
创建commonLoader
-
创建catalinaLoader
-
创建sharedLoader
注意: commonLoader是catalinaLoader和sharedLoader的父Loader.
以上创建loader都是通过调用createClassLoader方法, createClassLoader方法流程如下:
- 获取name + “.loader”配置属性, 例如对于commonLoader, 就是common.loader
- 根据*.loader生成repository列表, 稍后找ClassLoader需要用到
- 调用ClassLoaderFactory.createClassLoader方法
- 生成java.net.URLClassLoader对象
-
-
将catalinaLoader设为currentThread的contextClassLoader
-
加载org.apache.catalina.startup.Catalina类, 并newInstance
-
调用org.apache.catalina.startup.Catalina类的setParentClassLoader方法, 将其parent ClassLoader设置为sharedLoader
-
catalinaDaemon赋值为org.apache.catalina.startup.Catalina的instance
通过反射调用catalinaDaemon的start方法:
org.apache.catalina.startup.Catalina类startup方法流程:
-
load()
-
initDirs(): 检查系统配置java.io.tmpdir
-
createStarterDigest
创建org.apache.tomcat.util.digest实例
注意: Digester是个维护XML和Java对象的库( 见 Apache Digester ), 动态添加了很多规则, 如:
-
当XML Parser扫描到<Server>时, 创建org.apache.catalina.core.StandardServer实例, 并保持其生命周期到</Server>
-
当XML Parser扫描到<Server><GlobalNamingResources>时, 创建org.apache.catalina.deploy.NamingResourceImpl实例
…
( 详见Catalina.java\createStarterDigester方法 )
个人感受: Digester是一个另类的依赖注入模型
-
-
取conf/server.xml, 并由digest进行解析
digest.push(this) // 将Catalina.java类实例作为Digest的object stack的root digest.parse(inputSource) // 解析这样Catalina.java的getServer()返回的便是Digestor的规则所创建的Server实例( org.apache.catalina.core.StandardServer )
-
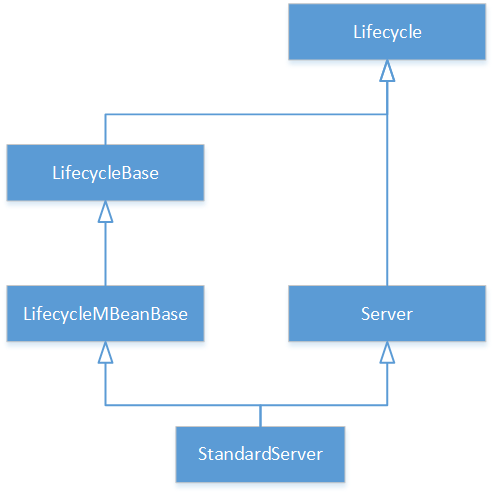
调用StandardServer的init
附: StandardServer的继承关系如下图:
附: Lifecycle的状态机如下:
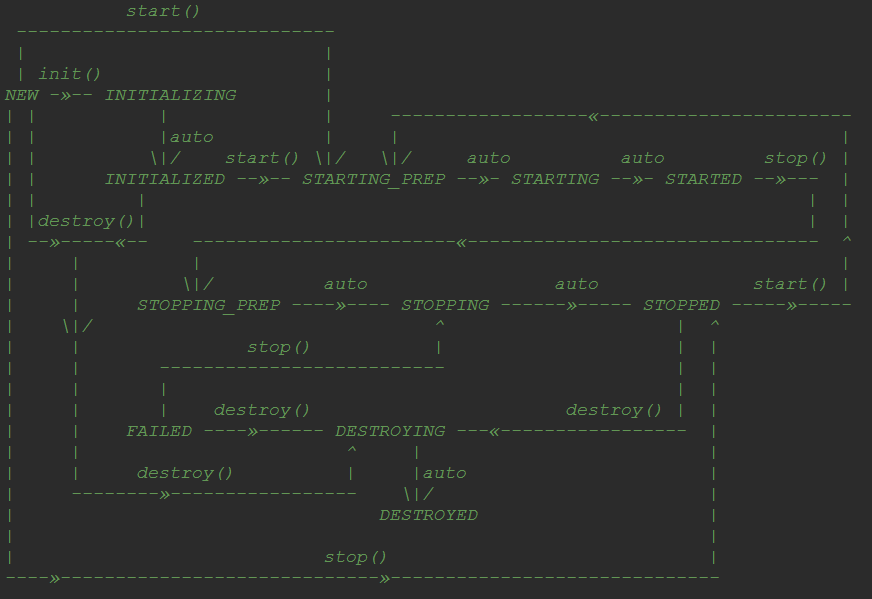
调用StandardServer的init, 但是因为StandardServer没有init方法, 实际调用到的是LifecycleBase的init:
LifecycleBase的init()流程:
-
Lifecycle状态迁移为INITIALIZING
-
调用initInternal(), 调用到的是StandardServer的initInternal:
-
新建StringCache对象, 注册Catalina:type=StringCache到MBean Server;
-
新建MBeanFactor对象, 将container设置为当前的StandardServer实例, 注册Catalina:type=MBeanFactory到MBean Server;
-
调用NamingResourceImpl的initInternal:
- 为resources, env, resourceLinks调用createMBean
-
把common和shared的classes添加到ExtensionValidator
-
调用services的init() ( services是由conf\server.xml的
节点添加 ) StandardService的init()流程:
-
调用Executor的init
注意: Executor是在被Digestor在解析conf\server.xml时, 解析到
时添加, 用于定义线程池. -
初始化MapperListener实例 ( 用于listen virtualhosts的配置改变 )
-
调用Connector的init
注意: Connector是在被Digestor在解析conf\server.xml时, 解析到<Server><Service><Connector>时添加.
Digester在XML Parser到如下节点时:
... <Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" /> ...调用ConnectorCreateRule的begin()方法, 创建Connector对象, 放入digester的object stack栈顶.
创建Connector对象流程:
-
获取传入的protocol ( “HTTP/1.1”, “AJP/1.3” )
-
加载protocolHandlerClassName类 ( org.apache.coyote.http11.Http11NioProtocol )
-
newInstance创建Http11NioProtocol类实例, 赋值给this.protocolHandler
/创建Connector对象流程
Connector的init流程:
-
创建CoyoteAdapter类实例, 赋值给protocolHandler的Adapter;
-
初始化protocolHandler ( protocolHandler.init, 即调到Http11NioProtocol的init )
Http11NioProtocol的init流程:
Http11NioProtocol的类结构如下:
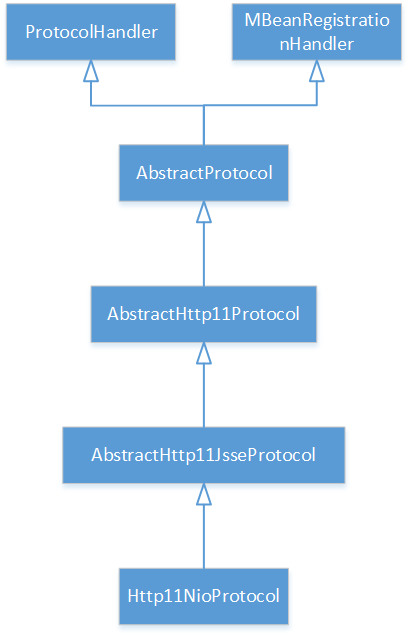
Http11NioProtocol类自身没有init方法, 故init方法调到的是父类AbstractHttp11JsseProtocol的init:
AbstractHttp11JsseProtocol的init()流程:
-
获取SSLImplementation类实例
-
AbstractProtocol的init方法:
AbstractProtocol的init()流程:
-
生成Catalina:type=ProtocolHandler,port=8080,address=xxx的ObjectName实例, 注册到MBean Server
-
生成Catalina:type=ThreadPool,name=xxx的ObjectName实例, 注册到MBean Server
-
生成Catalina:type=GlobalRequestProcessor,name=xxx的ObjectName实例, 注册到MBean Server
-
调用endpoint的init()方法, 这里endpoint指向NioEndpoint实例:
NioEndpoin的init()流程
-
调用bind()方法 ( 调到NioEndpoint的bind方法 ):
-
java.nio的调用:
ServerSocketChannel.open() -> bind, configureBlocking, setSoTimeout
-
org.apache.tomcat.util.net.NioSelectorPool的open调用
-
java.nio.channels.Selector的open调用
-
新的org.apache.tomcat.util.net.NioBlockingSelector实例
-
NioBlockingSelector的open调用:
-
创建新的BlockPoller线程实例 ( NioBlockingSelector.BlockPoller-线程计数 )
-
BlockPoller的start调用 ( run方法 ):
-
while循环
-
先处理events( 读, 写事件 )
-
select
-
dispatch select出来的事件
-
-
-
-
-
bindState置为BOUND_ON_INIT;
/NioEndpoin的init()流程
-
/AbstractProtocol的init()流程
-
/AbstractHttp11JsseProtocol的init()流程
/Http11NioProtocol的init流程
-
/Connector的init流程
-
/StandardService的init()流程
-
-
-
Lifecycle状态迁移为INITIALIZED
/LifecycleBase的init()流程
-
-
-
Server的start()方法
调用StandardServer的start, 但是由于StandardServer没有start方法, 实际调用到的是LifecycleBase的start:
LifecycleBase的start()流程:
-
Lifecycle状态迁移为STARTING_PREP
-
调用startInternal ( 这里调到StandardServer的startInternal方法 )
StandardServer的startInteral()流程
-
触发Lifecycle的事件CONFIGURE_START_EVENT
-
Lifecycle状态设为STARTING
-
调用service的start
调用StandardService的start,但是由于StandardService没有start方法, 实际调到LifecycleBase的start, 再调到StandardService的startInternal
-
-
-
-
一个Java Memory Leak的跟踪处理过程
背景
项目中有一个工作流模型,如下图所示:
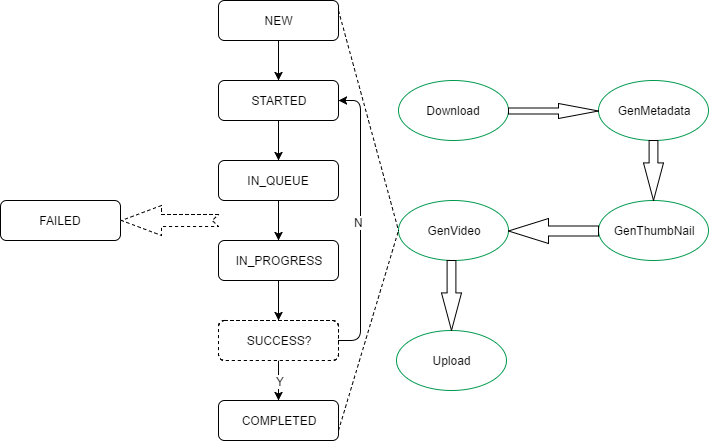
其中:
-
绿色椭圆框体为业务状态;
-
黑色长方框体为业务的作业状态;
-
每个业务状态都会把作业状态从NEW -> STARTED -> IN_QUEUE -> IN_PROGREE -> COMPLETED转一遍.
-
每一个业务状态都会有一个对应的CHECK状态. 在CHECK状态时, 如果SUCCESS检查没过, 则直接退回STARTED状态, 重走一遍CHECK(类似于轮询).
问题描述
当某个业务状态所对应的CHECK状态, 轮询次数过多时, 会发现运行jetty的java进程占用的虚拟内存容量过大, 造成页面加载极其缓慢.
ec2的2GB内存所剩无几:
[ec2-user@ip-172-31-25-152 ~]$ free -m total used free shared buffers cached Mem: 2003 1706 296 20 107 405 -/+ buffers/cache: 1193 809 Swap: 0 0 0top命令发现某java进程的虚拟内存达到了6GB之多, 驻留内存站到了700+MB, 对于2GB的ec2来说比例相当高了.
top - 09:19:19 up 82 days, 15:01, 1 user, load average: 0.58, 0.56, 0.35 Tasks: 89 total, 1 running, 88 sleeping, 0 stopped, 0 zombie Cpu(s): 15.7%us, 0.7%sy, 0.0%ni, 83.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st Mem: 2051472k total, 1748936k used, 302536k free, 110560k buffers Swap: 0k total, 0k used, 0k free, 415216k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 8478 ec2-user 20 0 5791m 776m 17m S 12.6 38.7 163:28.09 java 25888 postgres 20 0 329m 16m 13m S 1.3 0.8 0:10.20 postmaster 25911 postgres 20 0 329m 15m 13m S 1.3 0.8 0:08.96 postmaster 25996 postgres 20 0 330m 17m 13m S 1.0 0.9 0:02.05 postmaster 25983 postgres 20 0 330m 17m 13m S 0.7 0.9 0:02.68 postmaster 8537 ec2-user 20 0 2493m 154m 17m S 0.3 7.7 4:14.04 java 1 root 20 0 19636 2408 2084 S 0.0 0.1 0:05.12 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:51.00 ksoftirqd/0 4 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root 20 0 0 0 0 S 0.0 0.0 11:31.83 rcu_sched 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh 9 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs 11 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 netns 12 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 perf 15 root 20 0 0 0 0 S 0.0 0.0 0:00.02 xenwatch 20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 xenbus 21 root 20 0 0 0 0 S 0.0 0.0 2:49.92 kworker/0:1 129 root 20 0 0 0 0 S 0.0 0.0 0:02.30 khungtaskd 130 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 writeback 132 root 25 5 0 0 0 S 0.0 0.0 0:00.00 ksmd 133 root 39 19 0 0 0 S 0.0 0.0 0:00.00 khugepaged 134 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 crypto 135 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kintegrityd 136 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset 138 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kblockd 488 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 md查看对应进程, 发现正是运行jetty容器提供HTTP服务的进程:
[ec2-user@ip-172-31-25-152 ~]$ ps -ef| grep 8478 ec2-user 8478 1 11 May10 ? 02:43:37 java -jar /home/ec2-user/jetty-latest/start.jar ec2-user 26202 26167 0 09:19 pts/0 00:00:00 grep --color=auto 8478跟踪和分析过程
-
用jmap把问题进程的heap抓下来:
jmap -heap:format=b 8478jmap是JDK附带的工具, 可以通过指定PID把对应java进程的heap和memory dump出来.
上面的jmap命令运行结束后, 会在当前目录生成heap.bin文件.
-
将heap.bin下载到安装有Eclipse Memory Analysis Tool的机器上, 直接打开heap.bin
-
Eclipse Memory Analysis Tool提供了强大的图形化分析功能.
-
分析后发现大量的ChannelSftp对象存放在一个vector里, 被强引用, 占据了堆空间, 没有及时释放, 也无法被GC回收.
跟踪代码, 发现在业务状态所对应的CHECK状态时的动作是创建一个ssh Session连到ec2上, 检查对应业务状态的log文件是否包含有”SUCCESS”字串.
创建ssh Session的动作, 是通过com.jcraft.jsch包来做的, 流程如下:
-
创建com.jscraft.jsch.Session实例;
-
通过Session创建com.jscraft.jsch.ChannelSftp实例;
-
通过ChannelSftp获取远端ec2上文件的内容;
代码逻辑如下:
public String readTextFile(SshInfo sshInfo, String path){ ... try{ Session session = getSessionConnected(sshInfo); ChannelSftp sftpChannel = (ChannelSftp)session.openChannel("sftp"); sftpChannel.connect(); OutputStream outputStream = new OutputStream(); sftpChannel.get(path, outputStream); ... }catch(Exception e){ throw new AppException(...); } }com.jscraft.jsch是开源的第三方包, 下载了一份源码.
跟踪到ChannelSftp类, 发现:
-
在ChannelSftp的Channel基类的构造函数中, 将Channel对象自身加到一个static Vector pool中去;
-
在Channel基类的del方法中, 才将该Channel对象从pool中移除; ( 移除后强引用关系丢失, GC才会自动回收Channel对象 )
继续跟踪在何处调到del, 发现在Channel的disconnect方法会调到del方法.
逻辑和rootcause很清晰了, ChannelSftp用完后要显式的调用disconnect, ChannelSftp对象才能被GC回收.
真是一个低级错误.
-
-
Linux内核网络子系统源码分析(2) -- connect系统调用
- connect系统调用
- inet_stream_connect流程
- tcp_v4_connect流程
- 1. 从connect系统调用传入的struct sockaddr取出destination address, destination port, 并取得nexthop(如果struct inet_sock的struct ip_options_rcu有设置, nexthop为struct ip_option的faddr), 然后调用ip_route_connect进行寻路, 取得struct rtable;
- 2. 根据IP寻路的结果, 确定destination address, destination port
- 3. 设置默认TCP_MSS ( IPv4默认为536 )
- 4. tcp状态设为TCP_SYN_SENT
- 5. 将struct sock插入bind链表中
- 6. 调用ip_route_newports;
- 7. 为tcp生成sequence number, 赋给struct sock的write_seq成员;
- 8. 调用tcp_connect方法
- 8.1 分配struct sk_buff
- 8.2 在struct sk_buff中的tcp_skb_cb部分的tcp_flags字段, 设置SYN标志, 设置seq, end_seq, gso_* (什么是gso?)
- 8.3 根据sysctl_tcp_ecn, 设置tcp_flags字段中的ECN, CWR标志
- 8.4 给struct sk_buff打上时间戳
- 8.5 减struct sk_buff引用
- 8.6 调用__skb_queue_tail, 将struct sk_buff挂到struct sock的sk_write_queue
- 8.7 调用tcp_transmit_skb方法进入tcp层实际的处理和传输过程
- tcp_transmit_skb流程
- 1. 如果clone_it为1,调用skb_clone方法clone一个sk_buff, 注意此处只是克隆数据结构,packet data只是加引用计数;
- 2. 计算tcp头部空间大小tcp_header_size: sizeof(struct tcphdr) + tcp_options_size
- 3. 使用tcp_header_size来构建tcp头部, 包括设置source port, dest port, seq, ack_seq, window等
- 4. 调用struct inet_connection_sock的icsk_af_ops的queue_xmit方法 ( 该函数指针在tcp_v4_init_sock方法中初始化, 指向ip_output.c的ip_queue_xmit )
- ip_queue_xmit方法 (IP层实际的处理和传输过程)
- ip_output方法
- dev_queue_xmit方法
接《Linux内核网络子系统源码分析(1) – socket系统调用和关键数据结构》一文, 继续往下, 阅读Linux内核子系统connect系统调用流程源码.
由于网络子系统数据结构交错复杂, 先上一张数据结构关系图, 便于后文描述:
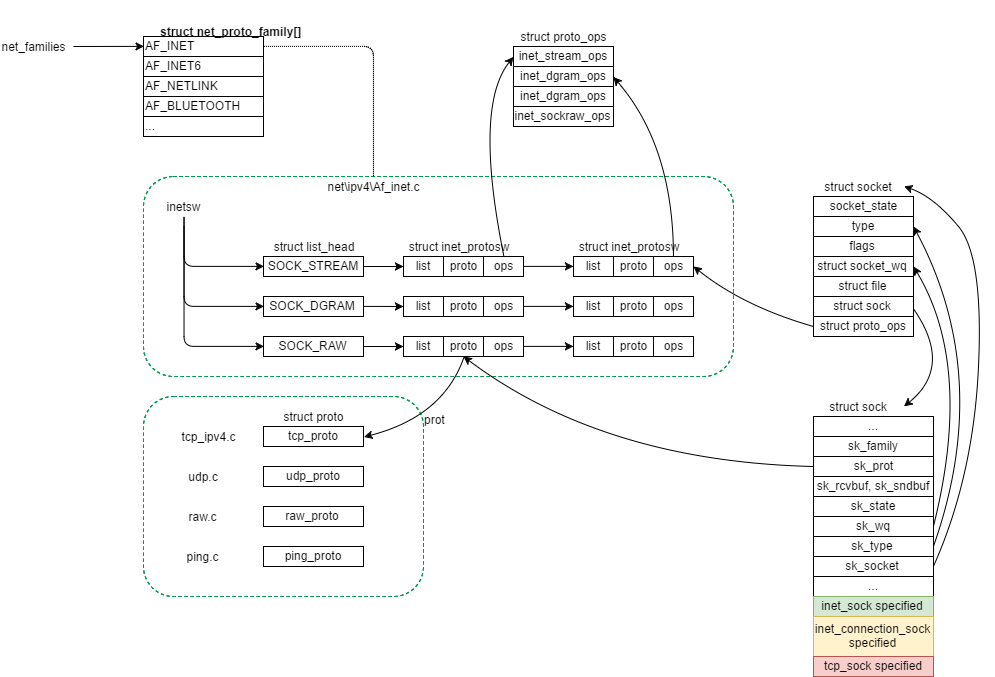
connect系统调用
connect系统调用的作用为连接server端正在listen的socket, connect系统调用由client端调用, 接口原型为:
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);connect系统调用实现入口位于Linux内核的网络子系统顶层代码中(net\socket.c).
暴露出来的connect接口指向函数为kernel_connect:
int kernel_connect(struct socket *sock, struct sockaddr *addr, int addrlen, int flags) { return sock->ops->connect(sock, addr, addrlen, flags); } EXPORT_SYMBOL(kernel_connect);对于net\ipv4\这个family来说, 结合文首图得知, sock->ops指向inetsw_array对应type的ops.
type为SOCK_STREAM, prot指向tcp_prot, ops指向inet_stream_ops
sock->ops->connect指向inet_stream_ops的connect, 即inet_stream_connect.
inet_stream_connect流程
1. 取struct socket内部的struct sock成员指针指向的struct sock; (见文首图很清晰)
2. 根据struct socket的socket_state类型字段:
-
SS_CONNECTED/SS_CONNECTING(略过)
-
SS_UNCONNECTED: 调用struct sock的sk_prot的connect函数( 这里即指向tcp_proc的connect, 方法名为tcp_v4_connect )
tcp_v4_connect流程
1. 从connect系统调用传入的struct sockaddr取出destination address, destination port, 并取得nexthop(如果struct inet_sock的struct ip_options_rcu有设置, nexthop为struct ip_option的faddr), 然后调用ip_route_connect进行寻路, 取得struct rtable;
问题: struct inet_sock的struct ip_options_rcu *inet_opt在何处设置?
2. 根据IP寻路的结果, 确定destination address, destination port
3. 设置默认TCP_MSS ( IPv4默认为536 )
4. tcp状态设为TCP_SYN_SENT
tcp_set_state(sk, TCP_SYN_SENT);5. 将struct sock插入bind链表中
err = inet_hash_connect(&tcp_death_row, sk);*在这一步之前source port可能还为0(对于client端调用socket后直接调用connect不经过bind的情况, source port为0).
所以inet_hash_connect方法会生成一个随机的source port, 赋给struct inet_sk的inet_sport成员.*
6. 调用ip_route_newports;
7. 为tcp生成sequence number, 赋给struct sock的write_seq成员;
8. 调用tcp_connect方法
8.1 分配struct sk_buff
8.2 在struct sk_buff中的tcp_skb_cb部分的tcp_flags字段, 设置SYN标志, 设置seq, end_seq, gso_* (什么是gso?)
8.3 根据sysctl_tcp_ecn, 设置tcp_flags字段中的ECN, CWR标志
8.4 给struct sk_buff打上时间戳
8.5 减struct sk_buff引用
8.6 调用__skb_queue_tail, 将struct sk_buff挂到struct sock的sk_write_queue
8.7 调用tcp_transmit_skb方法进入tcp层实际的处理和传输过程
tcp_transmit_skb流程
此方法开始TCP层实际的头部数据处理和往下层传输.
tcp_transmit_skb方法接口如下:
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask)1. 如果clone_it为1,调用skb_clone方法clone一个sk_buff, 注意此处只是克隆数据结构,packet data只是加引用计数;
skb_clone方法克隆的struct sk_buff不属于任何socket.
2. 计算tcp头部空间大小tcp_header_size: sizeof(struct tcphdr) + tcp_options_size
3. 使用tcp_header_size来构建tcp头部, 包括设置source port, dest port, seq, ack_seq, window等
4. 调用struct inet_connection_sock的icsk_af_ops的queue_xmit方法 ( 该函数指针在tcp_v4_init_sock方法中初始化, 指向ip_output.c的ip_queue_xmit )
ip_queue_xmit方法 (IP层实际的处理和传输过程)
1. 加ip头部
2. ip_local_out -> __ip_local_out -> nf_hook(IPV4, LOCAL_OUT, …), 此处进入netfilter子系统, 若允许pass, 返回1, 调用dst_output
此处是第一次碰到netfilter子系统, 在Linux内核网络子系统中, Netfilter相当于一个hook系统, 在不同的时间点进行filter, 有如下几个大的时间点:
enum nf_inet_hooks{ NF_INET_PRE_ROUTING, NF_INET_LOCAL_IN, NF_INET_FORWARD, NF_INET_LOCAL_OUT, NF_INET_POST_ROUTING, NF_INET_NUMHOOK }3. dst_output方法:
return skb_dst(skb)->output(skb);struct dst_entry的output方法函数指针在net\ipv4\route.c的__mkroute_output得到赋值, 指向ip_output方法.
ip_output方法
1. 获取struct net_device
2. 再次调用netfilter, 进行POST_ROUTING的filter. filter的结果为pass则调用ip_finish_output.
ip_finish_output -> 是否需要分片? ip_fragment() : ip_finish_output2()
先描述ip_finish_output2()这条线的流程.
3. 获取struct dst的struct neighbour成员
struct neighbour有一个NUD信息, 全称为“neighbour unreachability detection”; (此处应该补一张structure neighbour的结构图)
依次调用neigh_output -> neigh_hh_output, 最终调用到dev_queue_xmit方法
dev_queue_xmit方法
struct net_device -> struct netdev_queue -> struct Qdisc
调用struct Qdisc的enqueue方法将struct sk_buff挂入队列中.
struct Qdisc有多种实现, 实现在net\sched\sch_*.c中, 有fifo, generic, dsmark, cbq, choke等(留待日后细分析).
一个connect过程的调用框图如下:
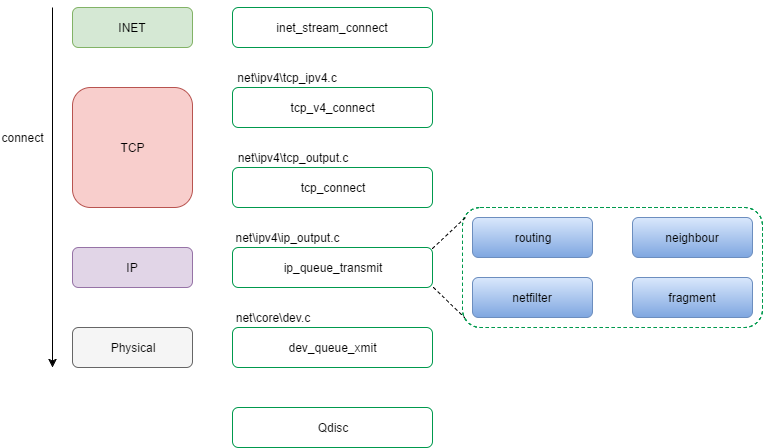
- connect系统调用
-
对j8ql的一个enhancement
最近使用j8ql做ORM搭建了一套内部的Web Service/Web UI.
j8ql是比较小众的一个ORM类库, 主打轻量.
为什么不用Hibernate, MyBatis? 以前用过这两者, MyBatis是使用xml做Mapper, 实在不喜欢,配置也过于复杂, 造成本来就很小的Web Service应用太重.
这套内部的Web Service有批量插入的需求, 大概是数万条记录的批量插入.
为了提高性能, 采取batch insert的方式.
由于batch insert后, 需要更新另外一张关系表, 故需要取得batch insert生成的键值.
j8ql对java.sql的PreparedStatement和Statement类做了封装, 将部分Statement的接口作为API提供给应用使用.
j8ql的executeBatch接口封装了Statement的executeBatch接口, 返回的是int[], 代表insert的结果成功还是失败.
如果需要取得batch insert的键值, j8ql没有提供方式.
遍寻无解的时候, 发现java.sql的Statement接口有一个getGeneratedKeys的方法, 用于获取该Statement运行时auto-generated keys, 正是我所需要的方法.
问题是j8ql的Runner接口和RunnerImpl类并未暴露这个getGeneratedKeys.
只能自己搞了, 于是对j8ql做了如下改动:
- 为RunnerImpl新增了一个List
成员, 用于保存PreparedStatement/Statement对象执行完executeBatch后调用getGeneratedKeys获取的结果; - 为Runner新增了一个getGeneratedKeys方法, 返回这个List
成员.
代码改完, 测试过程中, 发现在PreparedStatement/Statement在executeBatch后调用PreparedStatement/Statement的getGeneratedKeys依然取不到生成的键值.
Google后发现, Statement在prepateStatement时, 需要设置第二个参数autoGeneratedKeys为1, 方能使getGeneratedKeys返回结果.
UT完成后, 大功告成.
生成pull request提交给j8ql的owner做review和merge:
https://github.com/BriteSnow/j8ql/pull/12
- 为RunnerImpl新增了一个List